Competitions




 For the full English version of the competition rules, please click here.
For the full English version of the competition rules, please click here.
(More)
For the full English version of the competition rules, please click here.
(More)
本屆挑戰賽聚焦在從龐大且關係複雜的轉帳交易資料,找出其中不合理的交易模式。參賽者需要拆解交易發生的時間線,分析交易金額以及交易對手,找出未來會被判定為警示的帳戶。
現在就報名參加挑戰吧! (More)
For the full English version of the competition rules, please click here.
針對桌球的技戰術分析,本團隊已開發出桌球智慧球拍,用以蒐集選手揮拍資料,啟動了桌球大數據的研究,能夠深入分析球員回擊方式與揮拍力道是否穩定,提高選手實力評估的精準度,參賽者將運用選手揮拍資料訓練模型,進行性別、持拍手、球齡與選手等級分類。期盼透過本競賽,誠摯邀集具機器學習、數據分析專長的專家與高手,訓練出高辨識率的選手分級模型,進而推動並普及桌球技戰術分析相關研究與應用。
(More)
(More)
在大型語言模型加速催化各式技術的年代,語言模型的開發週期越來越短、效能越來越強。隨著大型語言模型的問世,金融業龐大且複雜的資料已經不再是語料檢索無法高度泛化的障礙,而是逐漸被解決的問題。
本屆挑戰賽聚焦在金融問答領域,提供豐富的資料庫供參賽者使用。參賽者需設計機制以提高檢索結果的準確性,包括從提供的語料中找出完整回答問題的正確資料等基本要求,以及應用大型語言模型的生成能力,產出正確且完整的回答。
準備好了的話,現在就報名參加挑戰吧!
(More)
For the full English version of the competition rules, please click here.
(More)
目前國內外同時包含生成式AI與AI無人機的競賽數量很少,此競賽將兩者結合,期望參賽者可以對此兩者有更加深入的理解與能力來應用在真實環境中。
Click here to DOWNLOAD competition
description English version
目前國內外同時包含生成式AI與AI無人機的競賽數量很少,此競賽將兩者結合,期望參賽者可以對此兩者有更加深入的理解與能力來應用在真實環境中。
Click here to DOWNLOAD competition
description English version
Click here to DOWNLOAD competition
description English version
Click here to DOWNLOAD competition
description English version
因應後疫情時代與國際社會等重大事件的發生,顧客的消費習慣、詐騙集團攻擊手法的改變,讓我們重現第3屆的主題:信用卡盜刷偵測,為銀行風控再提升。期望透過學術與產業界間的集思廣益,共同找出與時俱進的最佳解方,為臺灣有序、健康的金融環境盡一份心力!
本屆挑戰賽以信用卡冒用偵測為發想,提供參賽者去識別化後的顧客交易紀錄與最終警示盜刷樣態等資料,讓參賽者設計演算法並建立模型,篩選出應進行告警的可疑交易活動,進而提升冒用盜刷的攔截率。
(More)
人工智慧熱潮席捲,於商業應用之潛力漸露鋒芒,長期受市場關注的房地產正面臨著AI所帶來的挑戰與機遇。永豐金控非常重視人工智慧技術的發展與人才,我們正在尋找「不動產估價現值預測」高手,期望藉由人工智慧技術的應用,為每一筆房產找出最適的價值。成為房屋估價王,還有機會抱走高額獎金,歡迎各路好手前來挑戰,也為台灣房市共創一份心力!
(More)
本競賽需要應用深度學習方法,例如CNN, ResNet, Transformer,可達到初步的成果。如果要效果更好,需要設計擷取各種feature方法,或是使用meta learning, few-shot learning, GAN或是強化式學習方法MCTS, Alpha Zero等進階方法。本競賽兼顧AI方法的廣度與深度,是大專學生很好的研究題目,可以訓練學生應用深度學習的能力。
Note : For competition information in English, please refer to related documents in "Download Dataset". (More)
在AICUP2023中,本競賽將提供一個事實資料庫以及陳述句 (claim),參賽者需要建立自動化的事實檢索與查核系統,以驗證陳述句的真偽。如果陳述句能夠「支持」或「反對」事實,系統也必須透過檢索資料庫中的文章來提供證據句。需要注意的是,由於事實有可能會隨時間推移而產生變化,參賽者只能使用我們提供的資料庫進行事實驗證。
(More)
(More)
議論探勘(argument mining)是近期廣受矚目的自然語言處理任務。該任務試圖從文句中找出人們的主張(claim),以及支持或反對這些主張的原因。這可視為輿論探勘(opinion mining)或情緒分析(sentiment analysis)的進階任務。基礎的議論探勘任務,是給定一個主張(claim)與一個前提(premise),由模型判斷兩者之間的議論關係,例如該項前提為支持或反駁該主張。換言之,這是一個典型的分類任務,判斷一組主張與前提的關係。對於這類的任務,目前的自然語言處理模型已能達到一定的效能,近期的深度學習技術也顯示模型已能掌握部份議論推理能力。然而,模型在提供分類預測之餘,究竟是如何得到該預測之結果,其中的解釋性要素則仍然未有充份的研究。
有鑑於此,本計畫以議論探勘為目標,希望能讓模型在預測文句之間支持或反駁的關係之外,找出文句之中關鍵性的片段,作為預測的佐證資訊。這類資訊可以讓研究人員更了解模型內部的行為、促進自然語言處理的研究,同時也可望將來在終端應用時,提供出模型的判斷依據,讓人類評估模型該次判斷的可靠程度。
(More)
(More)
對於金融業而言,洗錢防制是一個必然面對的難題與挑戰。犯罪者利用各種洗錢管道將非法資金漂白,以逃避司法機關的查緝與追訴,甚至將該犯罪所得再次利用於其他不法行為當中。金融機構若不積極審查各種由其經手的交易行為,則將淪為犯罪集團的漂白管道,除了損及自身商譽之外,又因為金融機構具有集合廣大人民資金的特性,而擾亂了金融市場秩序。除此之外,金融犯罪者不斷以新興科技或渠道從事不法所得的掩飾或隱匿行為,洗錢態樣推陳出新,致使金融業單靠人力顯然不足以辨識出可疑的犯罪活動。
玉山銀行非常重視企業社會責任與金融秩序的維護,更致力於導入人工智慧技術,加以應用於可疑交易活動的辨識服務之中。於每個營業日,玉山銀行根據各種事先定義的可疑活動態樣,篩選出疑似洗錢而應向法務部調查局申報的交易事件,並逐筆進行人工審查、撰寫調查報告。不過,如此一來不僅耗費大量的人力與工時,更有疏漏的可能存在,而現存累積符合申報的案件數量,也是影響模型訓練成效的關鍵因素之一。
於是,本次玉山人工智慧公開挑戰賽即以此業務痛點為題目發想,廣邀各界好手解決現行實務的瓶頸。玉山銀行將提供去識別化後的顧客帳戶交易與最終可疑交易申報(SAR)結果等資料,讓參賽者自行設計演算法以建立模型,更精準地篩選出應進行申報的可疑交易活動,降低可疑活動的誤報率。期望藉由人工智慧技術的應用,將人力保留給較複雜且艱困的案件審核作業,為台灣有序、健康的金融環境盡一份心力!
玉山銀行現正發出英雄帖!總獎金上看二十三萬,等你來挑戰!
(More)
但在模型開發及應用實際落地的過程中,碰到最棘手的挑戰就是:語音辨識模型有時候聽不懂顧客在講什麼!語言博大精深,同音不同字、同字不同音,再加上各式各樣的腔調,都大幅阻礙了模型辨識的精準程度,導致辨識結果有時詞不達意、甚至無法理解。
玉山銀行現正發出英雄帖!我們要找尋能夠拯救人工智慧世界的你!
本次競賽我們將提供給參賽者玉山語音模型辨識後去識別化的語句,讓參賽者挑戰將辨識結果修正成正確的語句。總獎金上看二十三萬,準備等你來挑戰!
競賽將以「模型訓練(2022/04/14 – 2022/06/13)」、「線上對決 – 模型準度 爭霸戰(測試賽:2022/05/30 – 2022/06/01,正式賽:2022/06/14 – 2022/06/17)」兩階段進行。
「模型訓練」階段進行方式如下:
- 參賽隊伍於 T-Brain 平台上註冊比賽(請各隊隊長妥善保存收到的手機簡訊驗證碼,將作為模型準度爭霸戰階段使用之驗證資料)。
- 參賽隊伍於 T-Brain 平台 Dataset Download 區下載訓練資料集,主辦單位將提供各大新聞內容微幅節錄之文字,並利用玉山語音合成模型產生的音檔,以及真實情境下的語音資料,再透過玉山語音模型辨識後所產生的至多Top 10最有可能的語句、音素符號(phoneme sequence)和正確語句作為訓練資料(注意:訓練資料為文字檔而非音檔)。為模擬真實情境下,語音雜訊較多造成人工標記困難,以及部分的人為疏失,資料集中的正確語句,仍可能包含人工標記錯誤的狀況,請參賽者務必做資料清理,以進行文字後修模型訓練。
- 參賽隊伍須加入玉山人工智慧公開挑戰賽 Slack Workspace 社群,掌握競賽第一手資訊(請參閱Dataset Download區:Slack Workspace連結)。
- 開始模型訓練!
- 參賽隊伍須提供 RESTful API Server 並將模型部署於此 API Server,並依照規範的API 服務形式開發,供「線上對決 – 模型準度爭霸戰」使用(請參閱Dataset Download區:API 開發及規格說明文件)。
- API 驗證期間(2022/05/10 - 2022/06/17)請透過Slack 與 E.SUN bot 對話進行 API 驗證。
註 1:請務必於 Slack 進行驗證,才能於測試賽與正式賽進行答題。
註 2:測試賽與正式賽期間,主辦方系統皆會以每日發題前「最後一次驗證且成功」之 API URL 做為隊伍的 API URL,故於比賽日期間,仍可於每日發題前認證 API。(發題中無法進行API驗證) - 需注意,各隊伍最後一次測試成功的 URL 將自動做為「線上對決 – 模型準度爭霸戰」認定之 API Endpoint(請參閱Dataset Download區:API 開發及規格說明文件)。
前置作業:參賽者須將「模型訓練」階段產出之模型打包成 API 並部署於 API Server 並完成驗證測試。
- 爭霸戰為期七天,包含三天測試賽(2022/05/30-2022/06/01),與四天正式賽(2022/06/14-2022/06/17),並將於每天的 18:00 舉行。測試賽會提供分數但不計入最終計分。
- 主辦單位將會使用 HTTP Request 方式驗證參賽者模型成效,每日多輪提問,提問步驟如下:
- 每輪提問一題 Inference API 呼叫,即為一個Request。
- 主辦單位將發送 HTTP request(POST 方法)提供題目(Inference),參賽者 API 需回傳模型運算結果,timeout 時間為 1 秒。題目與回傳的資料格式請詳見 Dataset Download區:API 開發及規格說明文件
- 同時會多輪發送,最多10題,即同時發出10個Requests。
- 若參賽者 API Server 無回應,包含timeout或HTTP status_code不為200的情況,主辦方會嘗試重新呼叫,每輪提供題目皆最多重新呼叫 2 次(共呼叫3次),若無回應或逾時則該輪以 0 分計算。
- 將以模型進行文字後修正的準確度作為積分(詳見下方評分方式),並於每日24:00 前於活動 Slack(channel # 公告區)公布當日累積積分排名,每日加總後積分為最終排名依據。
- 最終名次將於 2022/06/23 公布,需注意參賽隊伍之模型針對正式賽資料集的評分,需優於正式賽資料集未修正前的評分,尚具領獎資格。
預測說明
- 於測試及正式賽時,參賽者將收到玉山語音模型辨識後的至少Top1、至多Top 10最有可能的語句和音素符號(phoneme sequence),參賽者需回傳模型後修正的語句。
- 音素符號(phoneme sequence)使用拓展音標字母評估法(X-SAMPA)。
- 正確答案之語句均為繁體字字串,且不會有符號、英文。
- 若為數字字串,請以「一二三四五六七八九十」回覆,正確語句的數字字串不會有阿拉伯數字或大寫數字,如123或壹貳參。
- 為模擬真實情境下,語音雜訊較多造成人工標記困難,以及部分的人為疏失,資料集中的正確語句,仍可能包含人工標記錯誤,或是第3、4點說明不應出現的狀況,請參賽者務必做資料清理。
本競賽提供豐富獎項、雲端運算資源、軟體工具和訓練課程,協助參賽者在競賽過程中,具備堅強的實力及工具取得佳績,像是有機會運用全台最大的 AI 高速 GPU 運算雲端資源-TWCC,協助跨節點高效能運算快速執行大規模的應用程式,透過AIHPC高效能加速縮短計算時間、優化模型以產出最精準的競賽結果。 (More)
本競賽提供豐富獎項、雲端運算資源、軟體工具和訓練課程,協助參賽者在競賽過程中,具備堅強的實力及工具取得佳績,像是有機會運用全台最大的 AI 高速 GPU 運算雲端資源-TWCC,協助跨節點高效能運算快速執行大規模的應用程式,透過AIHPC高效能加速縮短計算時間、優化模型以產出最精準的競賽結果。
(More)

Click here to DOWNLOAD competition
description English version
【聰明消費來預3-信用卡消費類別推薦】
你知道嗎,全台灣信用卡流通量竟然遠遠勝過全國總人口,高達5100多萬張!
而將近每三個人就有一張玉山信用卡!
在台灣,多數人都有用信用卡消費的經驗,
銀行也推出各式各樣的行銷活動,期望吸引消費者使用該銀行信用卡,
但!這些行銷真的都是用戶想要的嗎?過多的行銷內容不會打擾顧客嗎?
玉山現正發出英雄帖!我們要找尋能夠預測未來的你!
本次競賽我們將提供參賽者去識別化後的信用卡消費資料及基本屬性資料,
只要你能透過機器學習,精準預測顧客最感興趣的三大消費類別排序,
讓行銷活動更貼近顧客的心,就有機會獲得高額獎金!
你還在等什麼?別再觀望了!
玉山人工智慧公開挑戰賽2021冬季賽,立刻手刀報名來挑戰!
競賽進行方式如下:
- 參賽隊伍在報名時程內於T-Brain平台上註冊比賽。
- 參賽隊伍須先加入玉山人工智慧公開挑戰賽Slack Workspace社群,掌握競賽第一手資訊(請參閱Dataset Download區:Slack Workspace連結)。
- 參賽隊伍在比賽時程內於 T-Brain 平台Dataset Download區下載訓練資料集,主辦單位將提供去識別化後的信用卡消費及基本屬性等資料(請參閱Dataset Download區:訓練資料集、訓練資料欄位說明)。
- 開始模型訓練!
- 將模型預測結果依照規定之檔案內容格式(請參閱Dataset Download區:需預測的顧客名單及提交檔案範例)上傳至Leaderboard系統,Leaderboard會對每次的提交結果進行評測。
- 參賽隊伍可以在比賽過程中提交預測結果,取得模型對Public資料的評分,並利用Public Leaderboard參考其他參賽隊伍的最佳分數。比賽結束時,將會以最後一次上傳的預測結果 作為Private Leaderboard的成績,主辦單位會以此結果進行最終排名。
- 最終名次將於2022/01/11 T-Brain平台上公布。
預測說明
- 預測每位顧客下個月份消費金額前三名的消費類別排序。
- 需預測的消費類別包含16種類,請僅針對這16類進行預測回傳。(請參閱Dataset Download區:需預測的消費類別)。
- 需預測的顧客即為訓練資料集的所有顧客,顧客名單以及提交欄位產出請參閱Dataset Download區:需預測的顧客名單及提交檔案範例。
- 請預測結果務必能夠排序出第一至第三名,不接受預測結果含有同名次之狀況,且每個顧客預測的第一至三名類別不得重複。
本次參賽者要以人工智慧演算法,實現鋼胚上印刷或手寫序號的自動判別,將有助於問題源的返溯及品質的控管。參賽者除了要能辨識正常印刷之序號(含數字及英文字母),還得針對手寫序號、序號上下顛倒、重複印刷序號、或序號模糊等情況做有效的處理,以發展出適合實際產線運作的序號辨識系統。
歡迎各路投入人工智慧好手,參加本次競賽,我們等著您來挑戰!
媒體報導
(More)
(More)
居家環境中有許多不同類型的聲音,舉凡吸塵器、警報器、門鈴、電視聲等,充斥著我們的生活。由 Tomofun 所開發的 Furbo 狗狗攝影機,結合攝影機、丟零食互動、AI 智慧通知三大功能,成為狗狗的專屬保姆。Furbo 已經在全球成功拯救了超過 1000 隻狗狗的生命,包括避免狗狗誤食、通知家中發生火災、還有通知有陌生人闖入家裡等,以此保護狗狗的安全。AI 產品落地對各家公司來說一直是艱難的考驗,Tomofun 秉持著 “bring joy and innovation to every pet lover in the world” 的精神,開發出 AI 智慧通知功能,第一時間通知主人家中可能發生的狀況,即時掌握毛孩的狀態。
Tomofun 為了致力於讓 Furbo 提供更好的 AI 服務,舉辦了「Tomofun 狗音辨識 AI 百萬挑戰賽」。在本次競賽當中,我們將提供居家環境中可能會發生的聲音,並請參賽者做出居家環境音的識別,藉此讓每個毛小孩家庭更加安全又安心。 本次競賽共包含兩場賽事,分別為「初賽 」和「 」。
- 初賽: 2021/05/10 – 2021/06/10 期間於 T-Brain 平台上傳分類結果,將以預測的分數作為排名依據,並根據繳交的報告,公布晉級決賽之隊伍。
- 決賽: 2021/07/17 於線上進行,將模擬 AI 服務落地的方式舉辦賽事,當天獲得優異成績之隊伍,就有機會獲得高額獎金。
你,識字嗎?-中文手寫影像辨識
在銀行業務中有各式重要手寫單據,但能想像光單一種類單據的人工登打,每日就會耗費21個人力小時!
現在我們要尋找影像辨識的好手,透過深度學習自動辨識圖片中的文字,以大幅降低人力處理重複性作業的成本。本次競賽將提供參賽者手寫中文字圖檔,透過CV演算法,只要能精準辨識圖片內手寫文字,就有機會獲得高額獎金!
各位參賽者,你,識字嗎?玉山人工智慧公開挑戰賽2021夏季賽,等你來挑戰!
競賽將以「模型訓練(2021/04/12 – 2021/06/14)」、「線上對決 – 模型準度爭霸戰(測試賽:2021/05/24 – 2021/05/26,正式賽:2021/06/15 – 2021/06/18)」兩階段進行。
「模型訓練」階段進行方式如下:
- 參賽隊伍於T-Brain平台上註冊比賽(請各隊隊長妥善保存收到的手機簡訊驗證碼,將作為模型準度爭霸戰階段使用之驗證資料)。
-
參賽隊伍於 T-Brain 平台Dataset Download區下載訓練資料集,主辦單位將提供手寫圖片資料集,為模擬真實情境,訓練資料集的檔名不一定為該圖片中正確的label,請參賽者務必做資料清理。
- 參賽隊伍須加入玉山人工公開智慧挑戰賽Slack Workspace社群,掌握競賽第一手資訊(請參閱Dataset Download區:Slack Workspace連結)。
- 開始模型訓練!
- 參賽隊伍須提供RESTful API Server並將模型部署於此API Server,並以API服務形式供「線上對決 – 模型準度爭霸戰」使用(請參閱Dataset Download區:API開發說明文件)。
-
API驗證期間(2021/05/10 - 2021/06/18)請透過 Slack 與 E.SUN bot 對話進行 API 驗證。
註1:請務必於 Slack 進行驗證,才能於測試賽與正式賽進行答題。
註2:測試賽與正式賽期間,主辦方系統皆會以每日發題前「最後一次驗證且成功」之 API URL做為隊伍的 API URL,故於比賽日期間,仍可於每日發題前認證 API。 - 需注意,各隊伍最後一次測試成功的URL將自動做為「線上對決 – 模型準度爭霸戰」認定之API Endpoint( 請參閱Dataset Download區:API開發說明文件)。
「線上對決 – 模型準度爭霸戰」階段進行方式如下:
前置作業:參賽者須將「模型訓練」階段產出之模型打包成API並部署於API Server並完成驗證測試。
-
爭霸戰為期七天,包含三天測試賽(2021/05/24-2021/05/26),與四天正式賽(2021/06/15- 2021/06/18),並將於每天的18:00舉行。測試賽會提供分數但不計入最終計分。
-
主辦單位將會使用HTTP Request方式驗證參賽者模型成效,每日多輪提問,每輪一題,提問步驟如下:
- 每輪提問一個Inference API呼叫。
- 主辦單位將發送HTTP request(POST 方法)提供題目(Inference),參賽者API需回傳模型運算結果,timeout時間為1秒。題目與回傳的資料格式請詳見Dataset Download區:API開發說明文件。
- 若參賽者API Server無回應,主辦方會嘗試重新呼叫,每輪提供題目皆最多呼叫3次,若無回應或逾時則該輪以0分計算。
- 將以模型辨識中文字的準確度作為積分(詳見下方評分方式),並於每日24:00前於活動Slack(channel # 公告區)公布當日累積積分排名,每日加總後積分為最終排名依據。
- 最終名次將於2021/06/25公布。
以下頁面內說明為「你,識字嗎? - 中文手寫影像辨識」之競賽細節:
預測說明
- 辨識圖檔中文字內容。
- 所有文字皆須回覆「繁體字」。
- 在正式賽的題目中,若該圖片中文字未存在於主辦單位提供之「training data dic」,請以string格式回覆"isnull"。亦即,若該題目圖檔中文字為「陳」,但該文字未出現在「training data dic」中,回覆「陳」則該題答錯,須回傳"isnull"。(請參閱Dataset Download區:training data dic )。
- 訓練資料集中的檔名不一定為該圖片中的正確label,請參賽者務必做資料清理。
場景文字檢測通常為場景文字辨識的前置步驟,即由畫面的像素中判斷文字出現的位置,以利後續針對該位置辨識可能的文字內容。場景文字檢測直接影響了文字辨識的準確度,本次賽事目標即為定位畫面中肉眼可識的文字位置。場景文字檢測受到許多因素所影響,包括場景中可能出現的多型態文字、多國文字、傾斜招牌文字、不同尺寸文字、外物遮蔽、類文字圖案紋理干擾、光線與陰影等。本賽事的目標場景為台灣市區街景,期望參賽者利用機器學習/深度學習技術,嘗試與開發適當的模型,以確偵測台灣街景畫面中的文字區域。
(More)

如何設計一個系統,能自動閱讀論文摘要後,標註並統整論文裡所涉及的演算法? 鑑於當今電腦科學的發展日新月異,演算法的更迭與演進以爆炸式的成長,歸納及統整這些演算法所需的人力將不復以往,而爬梳相關文獻所需的時間也往往讓研究者們深感無力。因此,讓機器自動梳理這些不斷推陳出新的演算法,將會是無可避免的嘗試。即便在人力可負擔的情形下,讓機器自動統整相關演算法,將可以讓研究者騰出時間做更有意義的事。
在本系列的競賽中,我們將嘗試以語意分析的技術解決一個令電腦科學研究者頭痛已久的問題:「如何設計一個能自動閱讀論文摘要,標注並統整論文中所發明、使用或用來比較的演算法的系統」。
競賽任務 [機器閱讀紀錄-課程挑戰賽]:
從arXiv的電腦科學相關論文摘要,預測出摘要所屬的類別(Theoretical Paper, Engineering Paper, Empirical Paper, Others)。需注意的是摘要可以有多個分類,例如: 摘要可以同時是Theoretical Paper和Engineering Paper。
(More)
Gotcha!人人都可以是反洗錢大師!
洗錢是指將犯罪不法所得,以各種手段掩飾、隱匿而使犯罪所得在形式上合法化的行為。近年來因國際洗錢與資助恐怖活動事件頻傳,國內吸金、電信詐騙案件也層出不窮,使得政府與各產業皆致力於洗錢防制(AML)工作。
一般來說,顧客與金融機構往來時,銀行需即時確認顧客身份,透過自動化系統比對出顧客是否列於AML焦點人物名單中。若能透過AI的協助定期更新AML焦點人物名單,並搭配自動化比對,將可大幅降低銀行執行AML作業的人力與時間成本。
本次競賽將提供參賽者公開新聞資料連結與相對應的焦點人物名單,希望大家集思廣益,透過NLP演算法,精準找出AML相關新聞焦點人物,不僅能協助優化AML焦點人物名單的更新作業,更有機會獲得高額獎金!
競賽將以「模型訓練( 2020/06/01 – 2020/07/22 )」、「線上對決 – 模型準度爭霸戰( 2020/07/22 – 2020/08/07 )」兩階段進行。
「模型訓練」進行方式如下:
- 參賽隊伍於T-Brain平台上註冊比賽(請各隊隊長妥善保存收到的手機簡訊驗證碼,將作為模型準度爭霸戰階段使用之驗證資料)
- 參賽隊伍於 T-Brain 平台Dataset Download區下載訓練資料集,主辦單位提供新聞連結與該新聞對應的焦點人物名單,參賽隊伍需自行實作爬蟲程式 (Crawler)獲取新聞內文。
- 參賽隊伍須加入玉山人工智慧挑戰賽Slack Workspace社群,掌握競賽第一手資訊(請參閱Dataset Download區:Slack Workspace連結)。
- 開始模型訓練!
- 參賽隊伍須提供RESTful API Server並將模型部署於此API Server,並以API服務形式供「線上對決 – 模型準度爭霸戰」使用(請參閱Dataset Download區:API開發說明文件)。
- API測試期間(2020/07/1 - 2020/07/22)請於活動Slack上提供API URL與 E.SUN bot進行API測試。
- 需注意,各隊伍最後一次測試成功的URL將自動做為「線上對決 – 模型準度爭霸戰」認定之API Endpoint(請參閱Dataset Download區:API開發說明文件)。
「線上對決 – 模型準度爭霸戰」階段進行方式如下:
前置作業:參賽者須將「模型訓練」階段產出之模型打包成API並部署於API Server即完成驗證測試。
- 爭霸戰為期九天,包含一天測試賽(2020/07/22),與八天正式賽(2020/07/27 - 2020/07/30及2020/08/03 - 2020/08/06),並將於每天的18:00舉行。測試賽會提供分數但不計入最終計分。
- 主辦單位將會使用HTTP Request方式驗證參賽者模型成效,每日多輪提問,每輪一題,提問步驟如下:
- 每輪提問包含一個Health Check API呼叫及一個Inference API呼叫。
- 主辦單位將以HTTP POST發送request呼叫參賽者的API Server進行健康狀態檢查(Health Check),當參賽者API Server收到呼叫後請立刻回傳response(Status Code:200)以表示API服務正常,timeout時間為1秒,若API Server未能於1秒內回應,則參賽隊伍之 API server 將被視為無法提供 API 服務。
- 主辦單位收到參賽者回傳Health Check response 後,將立即發送第二個HTTP request(POST 方法)提供題目(Inference),參賽者API需回傳模型運算結果,timeout時間為5秒。題目與回傳的資料格式請詳見Dataset Download區:API開發說明文件。
- 若參賽者API Server無回應,主辦方會嘗試重新呼叫,每輪健康狀態檢查與提供題目皆最多呼叫3次,若皆無回應或逾時則該輪以0分計算。需注意,若健康狀態檢查失敗則不會提供題目,該輪直接以0分計算,並繼續下一輪提問。
- 將以模型擷取之名單準確度作為積分(詳見下方評分方式),並於每日24:00前於活動Slack(channel # 公告區)公布當日累積積分排名,每日加總後積分為最終排名依據。
- 最終名次將於 2020/8/22公布。
下頁面內說明為「Gotcha!我抓得住你 - AML焦點人物辨識」之競賽細節:
預測說明
- 判斷該新聞內文是否含有AML相關焦點人物,並擷取出焦點人物名單(名單有可能為複數或為空)。
在台灣,20歲以上持有信用卡人數超過六成。因信用卡具備高回饋、延遲付款以及付款便利等特性,使得信用卡成為人們支付時不可或缺的工具。不過隨著科技的日新月異,不肖分子也針對此支付模式衍生出新的犯罪手法,即「信用卡盜刷」。
面對盜刷,一般民眾除了可以透過經常對帳、防止卡片資訊外洩等方式來避免外,國內外銀行及發卡組織近年也開始運用機器學習演算法找出潛在的盜刷交易,並及早因應。然而,盜刷的樣態千百種,到底什麼才是足以判斷為盜刷的關鍵因子呢?
本次競賽提供去識別信用卡交易授權資料,希望大家集思廣益,一同「反盜刷」!不僅捍衛自己的資產,守護身邊親友的財富,更有機會獲得高額獎金!
本次競賽共包含兩場獨立賽事,分別為「線上對決–模型準度爭霸戰」與「正面交鋒–創意做法擂台戰」。「線上對決–模型準度爭霸戰」為2019/09/06 – 2019/11/22於T-Brain平台上傳預測結果的競賽,將以預測準確度為排名依據,爭取最高12萬元的獎金;「正面交鋒–創意做法擂台戰」將於頒獎典禮當天舉行,獲獎資格為曾於「線上對決–模型準度爭霸戰」上傳成功且「非前六名」得獎的參賽者,每一獎項皆有新台幣5,000(含)元以上獎金,獲獎機率高達20%,只要您願意分享您的建模做法,就有機會將獎項抱回家!
以下頁面內所有說明為「線上對決–模型準度爭霸戰」之競賽細節,「正面交鋒–創意做法擂台戰」之進行內容、方式與報名連結,敬請參賽者密切注意主辦單位相關公告與通知。
預測說明
- 預測該筆交易是否為盜刷交易

Click here to DOWNLOAD competition description English version
如何設計一個系統,能自動閱讀論文摘要後,標註並統整論文裡所涉及的演算法? 鑑於當今電腦科學的發展日新月異,演算法的更迭與演進以爆炸式的成長,歸納及統整這些演算法所需的人力將不復以往,而爬梳相關文獻所需的時間也往往讓研究者們深感無力。因此,讓機器自動梳理這些不斷推陳出新的演算法,將會是無可避免的嘗試。即便在人力可負擔的情形下,讓機器自動統整相關演算法,將可以讓研究者騰出時間做更有意義的事。
在本系列的競賽中,我們將嘗試以語意分析的技術解決一個令電腦科學研究者頭痛已久的問題:「如何設計一個能自動閱讀論文摘要,標注並統整論文中所發明、使用或用來比較的演算法的系統」。
競賽任務2 [論文分類競賽]:
從arXiv的電腦科學相關論文摘要,預測出摘要所屬的類別(Theoretical Paper, Engineering Paper, Empirical Paper, Others)。需注意的是摘要可以有多個分類,例如: 摘要可以同時是Theoretical Paper和Engineering Paper。
(More)
Click here to DOWNLOAD competition description English version
如何設計一個系統,能自動閱讀論文摘要後,標註並統整論文裡所涉及的演算法? 鑑於當今電腦科學的發展日新月異,演算法的更迭與演進以爆炸式的成長,歸納及統整這些演算法所需的人力將不復以往,而爬梳相關文獻所需的時間也往往讓研究者們深感無力。因此,讓機器自動梳理這些不斷推陳出新的演算法,將會是無可避免的嘗試。即便在人力可負擔的情形下,讓機器自動統整相關演算法,將可以讓研究者騰出時間做更有意義的事。
在本系列的競賽中,我們將嘗試以語意分析的技術解決一個令電腦科學研究者頭痛已久的問題:「如何設計一個能自動閱讀論文摘要,標注並統整論文中所發明、使用或用來比較的演算法的系統」。
競賽任務1[論文標註競賽]:
我們將提供arXiv上電腦科學相關的論文摘要,參賽者需要使用這份資料預測論文中每個句子的分類(Background、Objectives、Methods、Results、Conclusions、Others)。需要注意的是句子可以有多個分類,例如:一個句子可以同時是Objective和Methods。
(More)
在保險業中,每個王牌業務員都有自己的一套銷售手法與良好的客戶關係經營。透過了解客戶需求,為客戶保單健檢,最後客制化出客戶想要保單組合,一步一步都是透過經驗的累積,才能夠行雲流水地成功推銷公司的保單。那麼客戶會願意購買保單,是業務員靠銷售手法創造出來的,還是客戶本身保險需求被挖掘出來的呢?事實上一次成功的保單交易,兩者缺一不可。
本次比賽的主要目的就是:「以現今機器學習的技術,挖掘出保險需求可能較高的客戶,並提供精準的銷售名單給業務員。」讓業務員可以花時間去經營、銷售較容易購買保險的客戶,把時間花在刀口上,去創造客戶對於保單的需求。
預測目標說明
在保險業中,客戶購買保單之行為模式相對複雜,本次競賽著重於單一險種,將預測在某一個時間點,公司既有客戶在未來三個月內是否會購買重疾險保單,為經典的二元分類問題。本競賽提供某年客戶特徵與購買商品之擬真資料,希望考驗參賽團隊進行資料分析以及創意發想,進而建立精準預測之客戶購買模型。
(More)
吃米要知米價,但身處在台灣各地的你真的知道房價嗎?
不知道也沒關係!一起透過比賽來了解吧!
購買屬於自己的房子,是我們一生中的大事,評估房子的好壞,不僅要考慮房子的大小、屋齡,甚至連附近的生活機能和未來發展性都是一大考量因素。然而在眾多的考量中,什麼才是影響房價高低至關重要的因素呢?
為了讓大家找出影響房價的潛在因子,本次比賽提供公開資訊及部分行內估價資料,希望大家集思廣益,結合AI力量、發揮見微知著的精神,一起朝一流的估價師邁進吧!
預測商品說明
- 不動產(RE):預測不動產總價
對於每間企業而言,顧客的喜好及購買行為一直都是企業關注的議題。而投放的行銷是否有效益,顧客會不會以購買表示支持,也是企業經營的重要生存關鍵。
在科技化的時代,人們習慣用網路瀏覽來探索商品,因此每間企業都努力的在網站上吸引顧客的眼球,期待顧客的買單,但顧客究竟會不會買單,傳統上我們只能事後得知。因此我們就在想,有沒有辦法透過模型進而預測顧客的購買行為呢?
本次比賽提供顧客在玉山官網上120天的瀏覽行為、基本屬性及交易/申請的去識別化行為資料,希望結合群眾智慧,預測顧客在之後的30天與玉山有哪些金融商品的往來。
預測商品說明
- 信用卡(CC):預測顧客是否申辦信用卡,不論後續是否核卡成功
- 信託類產品(WM):預測顧客是否以單筆/定期定額的方式,進行信託類產品(包括基金、債券、股票、ETF…)的申購/轉換
【註:申購定期定額基金只會顯示最早申購及轉換的時點,若後面月份只是持續扣款則不會出現在TBN_WM_TXN資料表當中】
- 信貸(LN):預測顧客是否進件,不論後續是否申貸成功
- 外匯(FX):預測顧客是否以台幣購買外幣
(More)
本次比賽主要目的是透過旅行社訂單的資料來預測該筆訂單最終是否成行。結合該筆訂單的訂單來源、該訂單所欲購買的旅行商品基本資訊,預測該筆訂單成行的機率。
(More)
開發新客戶所需要的成本是維護既有客戶的5倍,因此既有客戶的續約金額是企業重要的獲利指標。而掌握影響客戶續約或流失的關鍵,自然成為企業經營的重要課題。
保險商品的規格較複雜,通常無法直接判斷商品好壞。且個別客戶因實際事件而獲得賠償的頻次不一,因此購買之後也不一定有機會親身體驗商品價值。那到底什麼才是既有客戶續購保險商品的關鍵?在此,我們提供跨國產險公司近一年的客戶特徵與續約金額狀況,希望集合各位參賽者的智慧,找出有效預測既有客戶的續約金額模型或方法。
股價是否能被預測, 一直存在著正反兩派的觀點。有效市場派認為股價波動是隨機遊走而無法預測下一步會怎麼走, 往那個方向走。然而有效市假說似乎又與現實相悖, 許多研究顯示短期股價的相關性並不為零, 會有動量的存在, 而這是趨勢投資的基石。
因此我們提供參賽者 台灣上市/櫃公司近五年來的歷史每日股價(開盤,最高,最低,收盤)及成交量,希望能集合各位參賽者的智慧來找出預測股價的模型與方法。
參賽者依主辦單位所提供台灣上市/櫃近五年來的歷史每日股價(名目股價與調整股價)及成交量來預測台灣十八檔上市櫃成分證券ETF在下一週五天的漲跌及價格。
標的物
- 國內上市櫃成分證券ETF
- 共18檔ETF (排除正向2倍或反向ETF)
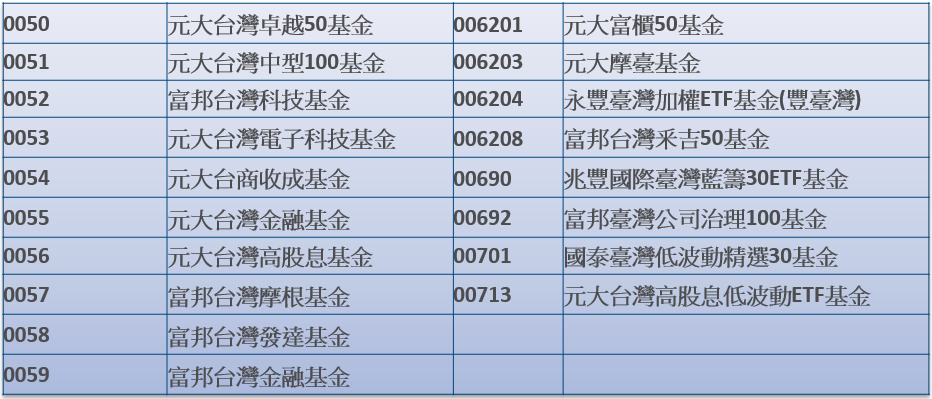
(More)
惡意程式偵測 (Malware Detection) 一直是資訊安全 (Cyber Security) 十分重要的一個環節,如果能有效偵測出家庭網路或企業網路中的惡意程式,並在程式進行惡意行為之前就阻擋及移除,就可以有效保護使用者的電腦及個人資料等資訊環境的安全。最傳統的防毒 (Antivirus) 是透過惡意程式中特定的程式區塊 (Signature) 來判斷惡意程式,需要資安專家來對惡意程式進行大量分析。最近因為機器學習 (Machine Learning) 的發展,使用機器學習來偵測病毒也成為防毒軟體必備的功能了。
然而傳統方式跟機器學習都需要對惡意程式的原始檔案進行掃描跟分析,當檔案數量及檔案大小很大的時候,就要花費較高的運算資源。所以要善用其他資訊來預判一個檔案的可疑程度,來降低掃描檔案實際所需要運算資源。本次競賽就是希望在不使用原始檔案 (file agnostic) 的情況下,以使用者電腦發現可疑檔案的紀錄,來判斷一個程式是不是惡意程式。
(More)